NLP in 2026 has transformed how businesses handle documents. Here's what you need to know:
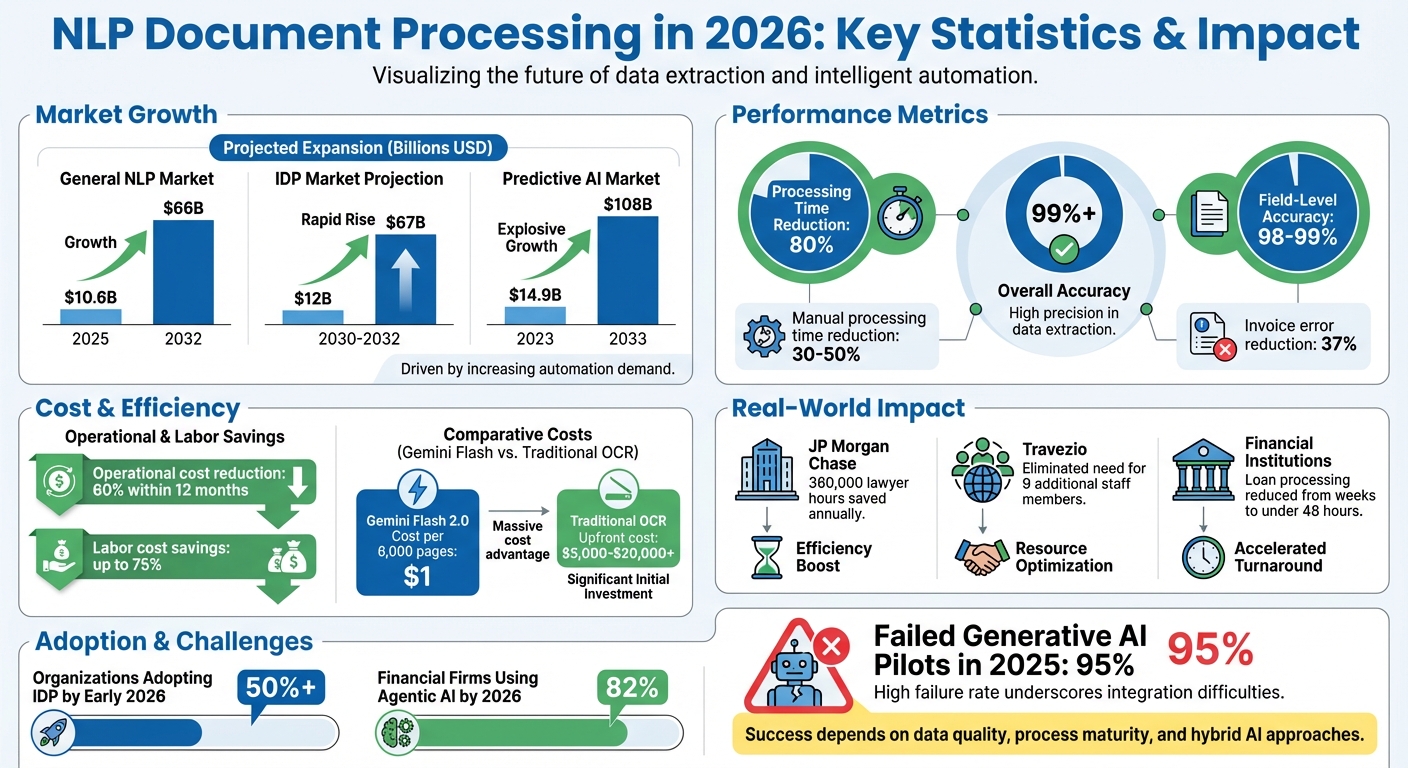
- Accuracy & Speed: Modern systems achieve over 99% accuracy, cutting processing times by up to 80%. Businesses save thousands of hours monthly by eliminating manual tasks.
- Market Growth: The document processing market is expected to grow from $10.6 billion in 2025 to $66 billion by 2032.
- Key Drivers: Advanced large language models (LLMs), better AI infrastructure, and multimodal capabilities (text, images, audio) are fueling adoption.
- Applications: Financial institutions, compliance workflows, and customer support are seeing massive improvements. For example, JP Morgan Chase now reviews legal documents in seconds, saving 360,000 lawyer hours annually.
- Hybrid Systems: Combining AI with rule-based systems ensures precision, especially for complex workflows like invoices and contracts. These systems reduce manual processing time by 30–50%.
- Challenges: Despite advancements, 95% of generative AI pilots failed in 2025 due to poor data structures. Success depends on data quality, process maturity, and integration strategies.
Takeaway: Businesses adopting NLP for document processing are seeing faster workflows, reduced costs, and improved accuracy. However, success hinges on proper planning, quality data, and hybrid approaches.
NLP Document Processing Statistics 2026: Market Growth, Accuracy & ROI
AI-Powered Document Processing
From OCR to Context-Aware Processing
By 2026, document processing has taken a giant leap forward. Systems now function as context-aware platforms that understand a document's intent, meaning, and layout - far beyond the basic text extraction of traditional OCR tools.
"OCR reads words, but IDP comprehends meaning." - Kushal Byatnal, Extend.ai
Modern platforms, powered by vision-language models like GPT-4 Vision and Gemini 2.5 Pro, create an internal "latent representation" of documents. This allows them to interpret sections and meanings much like a human would at first glance. With zero-shot semantic understanding, these systems can extract data and infer structure from raw content without needing predefined templates or domain-specific training. The result? Over 99% accuracy, eclipsing legacy OCR systems.
Cost efficiency has also improved dramatically. Gemini Flash 2.0, for instance, can process 6,000 pages for just $1, compared to the hefty upfront costs of traditional OCR software, which range from $5,000 to $20,000 plus per-page fees. These advanced systems also offer grounding and provenance, linking every extracted value to its exact location within the document. This feature ensures a robust audit trail, something older OCR technologies simply cannot provide.
"The goal is not a one-off parse. The goal is straight-through processing with an audit trail." - Vikram Kedlaya, Taskmonk
Another game-changing feature is iterative self-correction, or agentic parsing. These AI systems operate in loops, reflecting on their outputs, self-correcting errors, and ensuring results align with schema requirements. This shift from single-pass processing to reasoning-based workflows has made it possible to tackle complex, variable documents that would overwhelm older systems. Such advancements are transforming how organizations handle data extraction, making even the most intricate tasks more manageable.
Automated Data Extraction with NLP
Building on these advancements, modern NLP systems have redefined data extraction from unstructured documents. A standout innovation is dynamic schema generation, where AI automatically identifies and creates schemas for new document types - eliminating the need for manual template creation.
Take FedEx, for example. Between 2024 and 2025, they adopted Automation Anywhere's AI-based IDP system to process delivery receipts in real time. This enabled instant customer updates and improved operational transparency across their global network. Similarly, Travezio (formerly H&H Purchasing) used Zenphi's IDP solution to automate high-volume invoice processing. This implementation eliminated the need for 9 additional staff members during peak periods and removed the necessity for employee overtime.
Organizations adopting IDP systems report a 30-50% reduction in manual processing time for document-heavy tasks. For workflows that are critical to operations, these systems achieve field-level accuracy of 98-99%, significantly reducing the need for manual reviews and lowering operational risks. They also help cut invoice errors by up to 37%.
Vision-language models add another layer of capability by combining pixel-level visual analysis with text interpretation. This allows them to handle complex layouts, logos, and even noisy scans far better than traditional OCR. For instance, DeepSeek OCR can compress lengthy documents by 7-20× while maintaining over 90% accuracy by converting text into visual tokens.
"The winners will be those who fuse AI's adaptability with deterministic reliability - systems that can handle variation and still deliver predictable outcomes at scale." - Olivier Gomez, CEO, IAC.ai
Hybrid systems are quickly becoming the norm. These systems merge deterministic business rules for consistent fields with large language models (LLMs) for handling variable layouts like receipts or medical records. This approach ensures high accuracy for standard forms while maintaining the flexibility needed for unstructured data. To optimize efficiency, organizations use confidence thresholds to route only low-confidence extractions to human reviewers, enabling straight-through processing for clear, well-structured documents.
sbb-itb-97f6a47
Agents in action: Document processing 2.0 | OD814
Document Classification and Multimodal Processing
Modern NLP has taken document classification to a whole new level, thanks to integrated multimodal processing. By 2026, systems will seamlessly handle text, images, and handwriting in a single, unified workflow. Gone are the days of fragile, multi-step pipelines - now, Vision-Language Models can process document images in one smooth step. Cutting-edge architectures like DANIEL combine layout detection, text recognition, and data labeling into one streamlined process.
"The integration of pre-trained language models in the decoder side of the architecture improves the overall capability of the model not only for the text recognition task but most importantly for labeling the textual content." - Thomas Constum, LITIS, University of Rouen Normandie
The performance improvements are impressive. For example, LightOnOCR-2-1B processes 5.71 pages per second on H100 hardware while achieving an OlmOCR-Bench score of 83.2 - outperforming models nine times its size. These advanced systems also localize embedded images within documents, predicting normalized bounding boxes alongside text transcription. For industries like healthcare or retail, where documents often mix handwritten notes, logos, and printed text, this results in 82% fewer visual tokens and 71% lower latency compared to older methods. Additionally, template clustering helps detect layout changes early, preventing errors during data extraction.
This unified system isn't just limited to single-language documents - it works seamlessly across multiple languages.
Multilingual Document Handling
Multilingual processing has become a cornerstone of modern NLP, enabling businesses to handle documents in numerous languages without the need for separate models. With 43% of the global population bilingual and 13% trilingual, this capability is more relevant than ever. Compact models like PaddleOCR-VL-0.9B now support 109 languages while staying efficient enough for edge deployment. By sharing parameters, these models enable zero-shot translation, ensuring consistent processing regardless of the language.
A significant hurdle - code-switching, where documents switch between languages mid-sentence - has also been addressed. Older models saw a 15% drop in semantic accuracy with such text, but innovations like synthetic data augmentation and context-aware processing now maintain accuracy. Additionally, multimodal Retrieval-Augmented Generation (RAG) techniques have evolved to handle the complexity of multilingual documents. These systems can analyze text, tables, charts, and layouts while preserving formatting and terminology. This means organizations with international operations can process documents in their original form without losing critical structural details.
With these advancements, businesses can confidently manage diverse, mixed-media, and multilingual documents, no matter how complex.
Hybrid NLP Systems and Workflow Integration
Hybrid NLP systems are making waves by combining rule-based methods with AI's ability to adapt, creating more efficient document workflows. These systems pair AI's knack for recognizing patterns with rule-based checks to catch errors AI might overlook - like verifying invoice totals or flagging high-value transactions. This blend offers the flexibility of AI while preserving the control and auditability that businesses need for compliance.
Integration into cloud workflows is seamless, thanks to API-first architectures. Using REST/GraphQL APIs and webhooks, these systems feed structured, validated JSON data directly into ERP and CRM tools like SAP, Oracle, and Salesforce. This "grounded" data approach ensures every piece of extracted information can be traced back to its original document. These integrations build on earlier advances in automated data extraction and vision-language processing, creating a unified framework for document automation.
"AI-driven intelligent document processing has evolved from basic text recognition to true document understanding, enabling context-aware interpretation of both structured and unstructured data within integrated workflows."
– Michael Bochmann, Chief Product & Technology Officer, DocuWare
The impact is clear. Hybrid Intelligent Document Processing (IDP) can cut operational costs by 60% within a year, and by early 2026, over half of organizations piloting automation have adopted IDP solutions. In June 2025, the GA–LLM framework demonstrated its strength by achieving 98% constraint satisfaction in complex business reporting tasks, combining genetic algorithm optimization with large language model (LLM) generation. However, hybrid systems aren't without trade-offs: they deliver field-level accuracy of 95–99%, but processing times can stretch to 8–40+ seconds per page compared to 1–2 seconds for traditional parsing. Additionally, costs per page can be 10× to 50× higher due to iterative reasoning loops.
Dynamic Schema Generation for Variable Data
Hybrid systems now use Finite State Machines (FSMs) to enforce schema rules, ensuring outputs align with predefined JSON or Pydantic models. This eliminates malformed data, preventing disruptions in downstream cloud integrations.
Layout-aware parsing takes things further by preserving the structure of documents - headers, tables, and bounding boxes - rather than treating them as flat text. When a new invoice format appears, the system can identify fields, understand their relationships, and extract data without requiring new rules from developers. Schema versioning adds another layer of stability, helping businesses manage "schema drift" when document formats change unexpectedly. Tools like "Outlines" enforce schema validity during decoding, with a second validation step using Pydantic before data is stored in databases.
These advancements highlight the growing gap between pure AI solutions and hybrid systems in managing complex workflows.
AI-Only vs. Hybrid Systems: Comparison
Choosing between AI-only and hybrid systems depends on your business needs. While AI-only systems shine in creative tasks and general summarization, hybrid systems excel in structured, mission-critical processes.
| Feature | AI-Only Systems | Hybrid Systems |
|---|---|---|
| Accuracy | High for specific tasks; prone to hallucinations | 95–99% accuracy with schema enforcement |
| Adaptability | Limited to training data; struggles with layout changes | Combines AI flexibility with rule-based consistency for new formats |
| Cost | Lower initial setup; higher error-correction costs; faster processing (1–2 seconds per page) | Higher per-page cost (10×–50×) but reduces operational costs by 60% in 12 months |
| Use Cases | Best for simple, repetitive tasks, creative content, and general summaries | Ideal for unstructured, variable data like invoices, legal contracts, and regulatory filings |
For straightforward, high-volume document tasks, AI-only systems offer speed and cost advantages. But for workflows requiring precision and compliance, hybrid systems deliver better outcomes, even with higher processing costs per page.
Real-Time and Context-Aware NLP Applications
Advancements in automated extraction and hybrid integration have taken real-time NLP to the next level, reshaping how documents are managed in 2026. Unlike traditional batch processing, modern systems now analyze documents as they arrive - whether it’s an insurance claim, a loan application, or a support ticket. This proactive approach doesn’t just extract data; it interprets intent, identifies risks, and initiates actions within business workflows.
The results? Faster, more efficient processes. For instance, JP Morgan Chase's COIN system reviews commercial loan agreements in seconds, a task that previously required 360,000 hours of lawyer time annually.
The expansion of context windows has also been a game-changer. Models like Gemini 3 Pro can handle up to 2 million tokens, while Llama 4 manages an incredible 10 million tokens. When combined with multimodal retrieval-augmented generation, these systems can analyze text, tables, and charts simultaneously, offering a comprehensive understanding of unstructured data.
Event-Driven Document Ingestion
With improved context handling, document processing now reacts instantly to business events. Instead of waiting for scheduled batch runs, event-driven ingestion processes documents as soon as they’re received. For example, when a new order form arrives or a regulatory filing deadline looms, the system acts within seconds. Financial institutions leveraging this approach have slashed loan application times from weeks to under 48 hours.
This real-time method uses confidence-based routing: high-certainty documents are sent directly to ERP systems, while uncertain ones are flagged for human review. Extracted data is tagged automatically with metadata - like vendor names, processing statuses, and transaction IDs - making it immediately searchable and ready for analytics.
Predictive Insights from Processed Content
NLP systems in 2026 don’t just process data - they predict trends. By analyzing historical patterns, these systems can flag budget deviations, forecast payment cycles, and alert teams to upcoming contract renewals or regulatory changes before they become critical. The global predictive AI market reflects this growth, projected to rise from $14.9 billion in 2023 to $108 billion by 2033.
"Agents are most valuable when a task requires reasoning or action beyond simple automation. Their strength lies in deciding what to do next, justifying that decision, and acting across systems while remaining accountable for the outcome."
– Karyna Mihalevich, Chief Product Officer, Graip.AI
Agentic workflows push these capabilities even further. Instead of just flagging issues, systems actively pursue goals and make decisions across platforms. They validate inconsistencies, communicate with vendors about discrepancies, and even draft reports autonomously. However, implementing these workflows isn’t without challenges. As of 2025, 95% of generative AI pilots in enterprises failed to meet expectations, often due to inconsistent data structures. Organizations that view intelligent document processing as simple automation risk leaving 60–70% of its potential untapped.
These advancements pave the way for the next era of intelligent document workflows, blending current capabilities with future possibilities.
Conclusion: The Future of NLP in Document Processing
By 2026, document processing will have evolved far beyond simple digitization. Modern NLP systems will not only analyze and extract data but also reason, predict, and take action autonomously. This transformation will redefine workflows, from loan applications to compliance reviews, shifting from template-based approaches to agentic workflows. These systems will interpret documents in context, validate them against business rules, and enable smarter decision-making. Building on earlier advancements in hybrid systems and agentic workflows, this progress represents a major leap in managing unstructured data.
The global market for Intelligent Document Processing is estimated to grow to between $12 billion and $67 billion by 2030–2032, while the predictive AI market is expected to jump from $14.9 billion in 2023 to $108 billion by 2033. Businesses adopting advanced IDP solutions are already seeing results, such as a 30–50% reduction in manual processing time and labor cost savings of up to 75%. However, not all implementations succeed - about 95% of generative AI pilots in enterprises had stalled or failed by 2025. The gap between success and failure often boils down to factors like data readiness, process maturity, and strategic execution. These trends highlight the critical business strategies shaping the future.
Key Takeaways for Businesses
Organizations that successfully adopt NLP often follow these strategies:
- Focus on data quality before scaling AI: Poorly structured documents can undermine even the most advanced models.
- Adopt hybrid architectures: Combining AI's adaptability with strict business rules ensures compliance in industries like banking and healthcare.
- Track Straight-Through Processing (STP) rates: STP measures how many documents are handled without human intervention, offering a better metric than cost savings alone.
- Maintain human oversight: With 82% of financial firms using agentic AI solutions by 2026, explainability and accountability remain essential.
- Redefine staff roles: Shift employees from manual data entry to higher-value tasks like AI auditing, fraud detection, and exception management.
"2026 marks a fundamental shift from viewing IDP as a cost-reduction tool to recognizing it as a decision-support system. Organizations that treat IDP as merely automation are leaving 60–70% of value on the table."
– Hrishi Digital Solutions
Working with Consulting Firms for NLP Implementation
While internal strategies are important, expert guidance can make or break an NLP integration. The complexity of modern NLP systems often requires specialized consulting support. Consultants help businesses decide whether to build or buy their document processing infrastructure - a choice that can cost around $400,000 and take six months to develop internally. They also perform AI readiness assessments to identify gaps in document quality, process maturity, and governance, helping organizations avoid common pilot failures.
Consultants bring a valuable perspective, addressing the fact that technology itself accounts for only 20% of the implementation challenge. The remaining 80% involves change management, staff training, and workflow redesign. For regulated industries, consultants also ensure compliance with rules like GDPR, audit trails, and data residency requirements from the outset.
For organizations ready to take the next step, the Top Consulting Firms Directory offers access to specialists in digital transformation, IT infrastructure, and strategic implementation. These partnerships help businesses move beyond proof-of-concept projects to fully operational systems with measurable ROI - such as cutting invoice errors by 37%.
FAQs
What data prep is needed before using NLP for document processing?
Proper data preparation is the backbone of accurate and efficient NLP in document processing. It starts with organizing documents by type - think invoices, contracts, or reports. For scanned files, OCR (Optical Character Recognition) is crucial to transform them into machine-readable text.
Next comes preprocessing, which ensures the text is clean and consistent. This involves removing unnecessary noise, fixing formatting issues, and normalizing the text. Normalization typically includes steps like converting text to lowercase and stripping out special characters.
When working with large language models, the quality of your data is non-negotiable. Using validated, high-quality datasets minimizes risks such as biases or incorrect outputs, often referred to as "hallucinations." A well-prepared dataset lays the foundation for reliable and effective NLP outcomes.
When should I choose a hybrid system instead of AI-only?
When it comes to balancing accuracy, interpretability, and managing complex or variable document layouts, a hybrid system often stands out as the best choice. While AI-only systems are great at understanding semantics, they can falter when it comes to extracting structured data or dealing with handwritten notes. Hybrid systems bridge this gap by combining traditional techniques like OCR with advanced AI, enhancing overall performance. This makes them particularly effective for tasks that demand precision, such as processing financial reports or legal contracts - especially in scenarios where human oversight is essential.
How do I measure ROI beyond cost savings (like STP rates)?
When evaluating ROI, don't just focus on cost savings. Consider metrics like enhanced data accuracy, the influence of automation on strategic financial planning, and the decision support value provided by document AI. These benefits extend to areas like fraud detection and risk assessment, which play a key role in boosting operational efficiency and enabling more informed decision-making.


