When managing security in multi-cloud environments, the complexity of juggling AWS, Azure, and Google Cloud can create blind spots and delays in detecting incidents. This article outlines seven practical strategies to simplify detection and response across multiple cloud platforms:
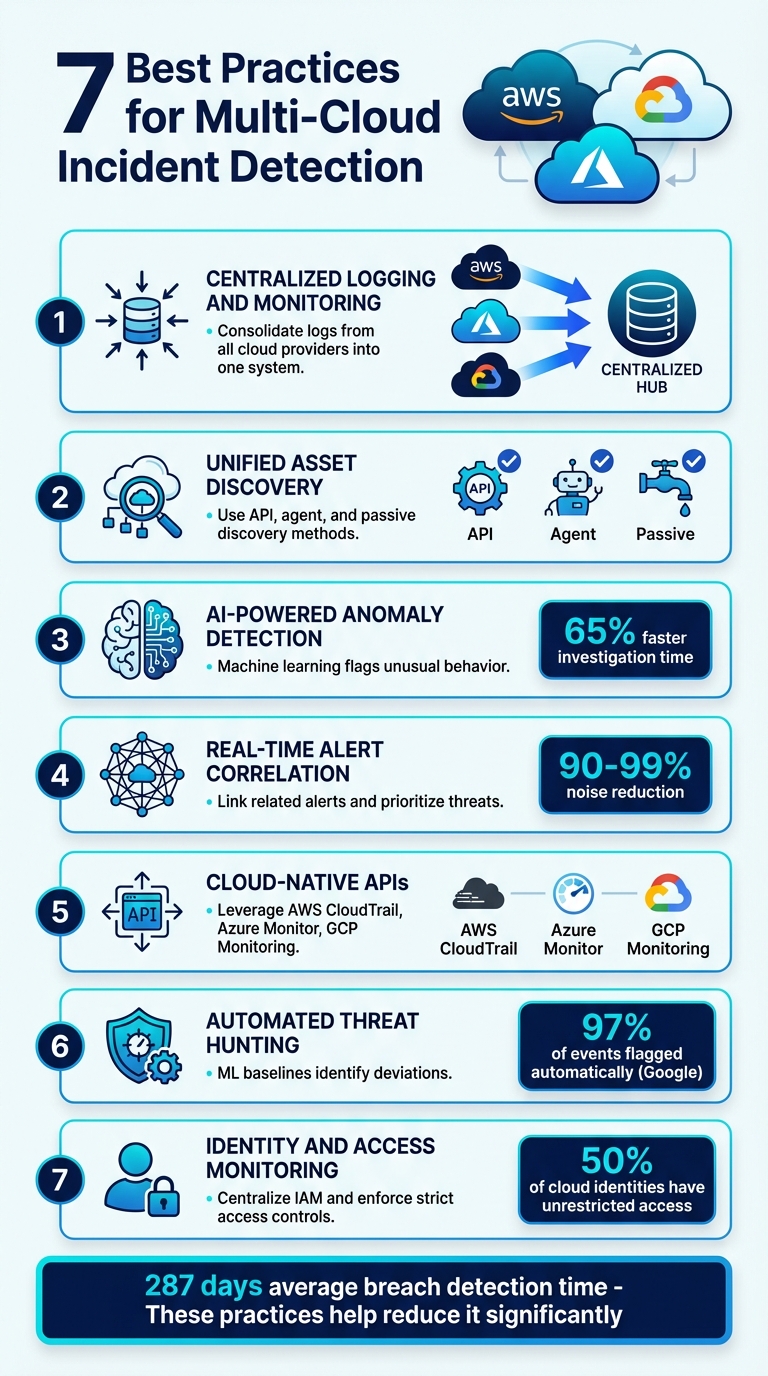
- Centralized Logging and Monitoring: Combine logs from all cloud providers into one system to eliminate silos and streamline visibility.
- Unified Asset Discovery: Use API, agent, and passive discovery methods to identify all resources, including hidden or rogue assets.
- AI-Powered Anomaly Detection: Implement machine learning to flag unusual behavior and establish activity baselines.
- Real-Time Alert Correlation: Reduce noise by linking related alerts and prioritizing high-confidence threats.
- Cloud-Native APIs: Leverage tools like AWS CloudTrail and Azure Monitor for continuous, real-time data collection.
- Automated Threat Hunting: Use machine learning baselines to identify deviations and uncover potential risks faster.
- Identity and Access Monitoring: Centralize identity management and enforce strict access controls to minimize risks.
These practices aim to reduce detection time, improve response efficiency, and address the unique challenges of multi-cloud environments. By implementing these strategies, you can better protect your cloud infrastructure and respond swiftly to potential threats.
7 Best Practices for Multi-Cloud Incident Detection
Cloud Security Detection & Response Strategies That Actually Work
1. Use Centralized Logging and Monitoring
Tackling the challenges of multi-cloud silos starts with centralized logging and monitoring. By consolidating data from AWS, Azure, and Google Cloud into a single system, you avoid the hassle of jumping between each provider's tools. This unified view simplifies the process and helps you overcome the varying logging formats and dashboards that often disrupt seamless management.
There are three primary ways to achieve this:
- Cloud-native tools like Azure Monitor paired with Azure Arc
- Third-party platforms such as Datadog
- Open-source solutions like OpenTelemetry for consistent log collection
The secret to success here is standardization. Each cloud provider generates logs in different formats - one might use JSON, while another relies on Syslog. To streamline this, normalize timestamps to UTC and map fields into a shared schema.
"The more clouds you have to manage and monitor, the more problems you're likely to run into."
- Michelle Artreche, observIQ
To optimize costs, implement regional aggregation to reduce inter-region data transfer fees. Additionally, use pull-based methods like Logstash to maintain data flow even if connections drop. For sensitive data, employ custom Fluent Bit configurations to filter out personally identifiable information (PII) before logs leave their original cloud environment.
This centralized approach not only simplifies monitoring but also lays the groundwork for effective incident detection across multiple cloud platforms.
2. Maintain Complete Visibility with Unified Asset Discovery
Keeping an eye on everything is the starting point for strong security. In multi-cloud setups, blind spots like rogue deployments, orphaned instances, or "shadow IT" can leave your defenses wide open. A unified asset discovery system tackles this by identifying and cataloging every resource across AWS, Azure, and Google Cloud - all from a single dashboard. This centralized view is essential for effective incident detection.
To cover all bases, combine API, agent, and passive discovery methods:
- API-based discovery pulls metadata directly from cloud providers, such as encryption settings and tags. However, it often misses OS-level details.
- Agent-based discovery steps in to fill that gap, identifying patch levels and installed software.
- Passive discovery goes even further by analyzing VPC flow logs, uncovering assets that don’t show up in official consoles. For instance, one passive discovery effort revealed 47 previously unknown hosts.
"For CISOs at today's large enterprises, the single greatest risk is not a novel threat but the fundamental uncertainty of what exists within their own environments."
- Faraz Siddiqui and Josh Pederson, Palo Alto Networks
Data normalization is key to making sense of raw information from different clouds. Each provider uses its own naming conventions - AWS uses "Instance ID", while Azure goes with "VM ID." A preprocessing layer standardizes these terms and removes empty fields before sending the data to your configuration management database (CMDB). This kind of optimization can have a big impact. For example, one organization cut its CMDB update queue from 10,000 to just 600 daily by using hash-based diffs, ensuring updates only occur when configurations genuinely change.
To stay ahead, integrate asset discovery into your CI/CD pipeline. By triggering discovery jobs every time you run terraform apply or helm upgrade, you can capture new assets right away. This proactive approach eliminates the lag between deployment and visibility, reducing the risk of security gaps.
3. Use AI-Powered Anomaly Detection and Behavioral Analytics
Traditional security tools rely on identifying known threat signatures. In contrast, AI-powered anomaly detection takes a different approach by learning what "normal" activity looks like within your system. This allows it to flag unusual behavior proactively. This shift is crucial, especially since 90% of cyberattacks now target cloud environments.
AI doesn't stop at anomaly detection - it also establishes behavioral baselines. Using machine learning, these tools analyze activity logs, network traffic, application usage, and API calls to understand typical patterns for users, agents, and systems [23, 25]. Over time, these models adapt to new workflows. When something suspicious - like impossible travel or privilege escalation - occurs, the system raises an alert [23, 25].
The results speak for themselves. Vertiv's CISO, Mike Orosz, implemented Google Security Operations and saw his team handle 22 times more data while cutting investigation times in half compared to their old system. Companies using AI-powered detection tools report a 65% faster mean time to investigate and a 50% faster mean time to respond, with automated workflows reducing alert triage times by up to 90% [22, 24].
To get the most out of these tools, start with clearly defined use cases and feed the system known malicious patterns to speed up training. During the initial 2–4 week stabilization period, human oversight is key to fine-tune the models. This process can reduce false positives significantly - from 20–40% with static thresholds to as low as 5–15% with well-trained AI systems.
"Behavioral detection is designed to detect new and novel threats instead of attack artifacts - which helps security teams pivot from responding to the aftermath of cyberattacks to preventing and pre-empting them in the first place." - James Todd, Field CTO, Cloudflare
4. Set Up Real-Time Alert Correlation and Triage
Real-time alert correlation and triage build on centralized logging and anomaly detection by turning scattered signals into actionable insights. In multi-cloud setups, alerts pour in from platforms like AWS GuardDuty, Azure Sentinel, and GCP Security Command Center. Without proper correlation, teams can drown in noise. Entity-based correlation is the answer - it links alerts by identifying shared elements such as user IDs, IP addresses, hostnames, or files across multiple systems. For instance, a suspicious login attempt in AWS might seem unrelated to unusual data access in Azure until you notice they both involve the same compromised IAM credential.
Time-window clustering is another key technique. It groups alerts that occur within short timeframes - ranging from 5 minutes to 2 hours - to reveal coordinated attacks. Tools like BigPanda can process and update these clusters in under 100 milliseconds, offering real-time insights. This automated approach reduces noise by 90%-99%, ensuring your team can focus on what matters most.
Composite detection logic takes things further by combining small, seemingly insignificant signals into a high-confidence alert. Imagine a login from an unusual location: it might not raise alarms on its own. But if it’s followed by privilege escalation and a large data upload within 30 minutes, a composite rule flags it as a serious threat. This method helps catch sophisticated attacks while cutting down on false positives.
"The context in which the alert happened determines its true criticality." - AWS Well-Architected Framework
To make alerts more actionable, enrich them with threat intelligence, asset ratings, and historical activity before they reach your SOC. Adopt an 80/20 split - 80% pattern-based correlation and 20% rules-based - to streamline triage. For example, a low-severity alert for one EC2 instance querying an unexpected domain might escalate to high severity when you discover hundreds of instances tied to the same compromised identity exhibiting the same behavior.
sbb-itb-97f6a47
5. Use Cloud-Native APIs for Continuous Data Collection
Cloud-native APIs are a game-changer for continuous data collection, especially when it comes to operating at the speed of the cloud. They provide direct access to critical security data, ensuring your team stays on top of threats in real time. Tools like AWS CloudTrail, Azure Monitor, and Google Cloud Monitoring API stream telemetry data as it happens, offering a clear view of "who did what" - a vital piece of the puzzle during incident investigations.
"CloudTrail as the source of truth. Every investigation starts with knowing exactly what happened and when." - Sygnia Team
Each major cloud provider offers native tools for seamless integration:
- AWS: EventBridge and Lambda automate immediate responses.
- Azure: Sentinel connectors pull logs directly from Defender for Cloud.
- Google Cloud: Log sinks with Pub/Sub manage real-time data flows.
- OCI: Functions push audit data effectively.
One standout feature of these APIs is event-driven ingestion. Unlike traditional polling methods, event-driven ingestion ensures updates are delivered instantly. Services like AWS Kinesis, Azure Event Hub, and GCP Pub/Sub can handle millions of events per second, ensuring logs flow directly to your SIEM without delays.
Best Practices for Secure and Efficient Data Collection
- Secure API Credentials: Store credentials in secret management tools like Google Secret Manager or OCI Vault instead of embedding them in scripts.
- Enforce Logging Controls: Use Service Control Policies (SCPs) to prevent unauthorized changes to logging configurations.
- AWS-Specific Tips: Enable CloudTrail across all regions and store logs in an immutable S3 bucket with encryption keys that are regularly rotated.
- Google Cloud-Specific Tips: Set up organization-level log sinks to automate log exports to BigQuery for faster analysis.
To standardize the collection of logs, metrics, and traces, consider adopting OpenTelemetry (OTel). This approach allows you to switch observability platforms without needing to rewrite application code. Additionally, tools like Fluent Bit can filter out sensitive data - such as Social Security numbers or credit card details - during ingestion, ensuring compliance and security before the data reaches cloud storage.
6. Automate Threat Hunting with Machine Learning Baselines
Keeping up with threats in today’s fast-moving multi-cloud environments is a challenge that manual threat hunting simply can’t meet. Infrastructure evolves quickly, and the sheer amount of telemetry data can easily overwhelm even the most skilled analysts. This is where machine learning (ML) baselines come into play. Unlike traditional anomaly alerts that react to issues, ML baselines proactively establish behavioral norms for users, workloads, and services across cloud platforms. Any significant deviation from these norms raises a red flag, enabling automated, continuous threat hunting.
"Machine learning, unlike conventional rule-based detection, is not dependent on prior knowledge of the threat activity we are looking for, and so can find emerging threats even before new threat intelligence is available." - Alvin Wen and Craig Chamberlain, Uptycs
The impact of automation is striking. At Google, 97% of security events are now flagged through automated processes rather than manual discovery. This shift has dramatically reduced attacker dwell time - from weeks to just hours - while cutting costs per ticket and allowing security teams to handle a larger volume of events.
Here’s how it works: ML systems use clustering algorithms like k-means to group similar entities based on attributes such as process initiation, network connections, system calls, and file access. Outliers - those behaviors that fall beyond the 95th percentile of normal activity - are flagged for further investigation. For example, Microsoft Sentinel’s Fusion engine uses 30 days of historical data for training, while other models may require a shorter training period of 7 to 21 days depending on the type of activity being monitored.
But ML baselines do more than just spot active threats. They also detect behavioral drift, which happens when workloads start to stray from their original configurations. This can indicate poor security practices or even unauthorized persistence mechanisms. High-value assets, like GitHub runners or software build systems, should be a priority for automated hunting since they are frequent targets for stealthy attacks. Interestingly, in threat hunting, spotting unusual behavior is often more actionable than noticing the absence of expected activity.
7. Monitor Identity and Access Across All Cloud Platforms
When managing security in multi-cloud environments, keeping a close eye on identity and access is absolutely critical. Identity has become the main line of defense. Here's a staggering fact: in 2023, over 50% of cloud identities had unrestricted access, but only 2% of those permissions were actually used. This mismatch creates a huge risk, contributing to the fact that 29% of incident investigations in 2024 involved cloud or SaaS environments.
As Unit 42 highlights:
"The majority of cloud breaches begin with compromised and overpermissioned identities." - Unit 42
The problem isn't just about human accounts. Non-human workload identities, like those assigned to apps, microservices, and containers, are a growing concern. These now make up 83% of all cloud identities, and 40% remain inactive for over 90 days. These dormant accounts are prime targets for attackers, who can use them to move laterally across cloud regions, services, or accounts.
Centralizing Identity Management
To address this, centralizing identity management is key. Using a single Identity Provider (IdP), like Okta or Microsoft Entra ID, across all cloud platforms creates a unified control point. This ensures that disabling one account immediately revokes access everywhere.
Additionally, streamlining all IAM audit logs - such as AWS CloudTrail, Azure activity logs, and GCP audit logs - into a centralized SIEM enables real-time monitoring and correlation. Tools like User and Entity Behavior Analytics (UEBA) can then establish behavioral norms and flag unusual activity, like odd API calls or unexpected access patterns. This setup simplifies cross-cloud identity management and strengthens security.
Real-World Example: Oracle and Microsoft Integration
In June 2023, Oracle and Microsoft users implemented a multi-cloud security workflow that synced Oracle Cloud Infrastructure (OCI) Audit events with an Azure Log Analytics Workspace. Using OCI Functions, IAM audit logs - such as user creation and login attempts - were automatically transferred to Microsoft Sentinel. This allowed security teams to monitor identity activity across both platforms in near real-time.
Strengthening Identity Security
To fully secure identities, consider these steps:
- Enforce Multi-Factor Authentication (MFA) at the IdP level.
- Audit inactive identities regularly to identify and remove unnecessary accounts.
- Implement Just-in-Time (JIT) access to grant elevated permissions only when absolutely necessary.
Conclusion
Managing incident detection across multi-cloud environments doesn't have to feel overwhelming. The seven practices discussed here work together to break down data silos that often arise when juggling AWS, Azure, and GCP, each with its own monitoring tools and formats. By centralizing logs and leveraging AI-driven analytics, you can respond quickly and effectively across all three platforms.
Reducing dwell time - the period an attacker operates before being detected - is absolutely crucial. On average, organizations take 287 days to identify and contain a breach. These practices aim to cut that time significantly, limiting exposure and stopping breaches before they spread across your infrastructure.
"A cloud IR partner likely has visibility into more environments and incidents than an individual organization. As such, a cloud IR partner can help improve readiness before an incident occurs and minimize the impact of an incident when it occurs." - Matthew Stephen, Mitiga
The value of expert guidance can't be overstated. Cloud incident response requires specialized knowledge. Consulting firms bring a wealth of threat intelligence, fast-response teams, and proactive readiness tools like tabletop exercises and chaos engineering. The Top Consulting Firms Directory can help you find firms that specialize in multi-cloud security, digital transformation, and cybersecurity, so you can partner with experts who understand the complexities of your environment.
These seven best practices work together to create a strong, unified defense strategy tailored to multi-cloud challenges. Shift from reactive problem-solving to proactive resilience. Start implementing these practices today to secure your multi-cloud environment. With the right mix of tools, processes, and expert support, you can safeguard your cloud operations while continuing to innovate and stay agile.
FAQs
What are the benefits of centralized logging for detecting incidents in multi-cloud environments?
Centralized logging makes it easier to spot and respond to incidents in multi-cloud environments by bringing together logs and events from different cloud platforms and on-premises systems into one unified location. This setup streamlines monitoring and real-time data analysis, helping teams quickly identify patterns, detect unusual activity, and take action faster.
With a consistent view of your entire infrastructure, centralized logging simplifies troubleshooting and speeds up investigations. It enables teams to connect the dots between logs from various sources, improving both the speed and accuracy of incident detection. This approach minimizes the chances of missing critical alerts and strengthens an organization’s ability to maintain visibility and improve security across complex hybrid and multi-cloud environments.
How does AI improve anomaly detection in multi-cloud environments?
AI plays a powerful role in spotting anomalies within multi-cloud environments, leveraging machine learning and deep learning to flag unusual patterns and potential threats as they happen. Unlike old-school rule-based systems, AI doesn't rely on predefined signatures, making it capable of identifying complex and evolving issues like zero-day attacks or insider threats.
By processing massive amounts of data from various cloud platforms, these AI-driven systems unify telemetry and automate responses to security incidents. Over time, they get smarter by learning from feedback and performance data, which helps organizations stay resilient, react faster, and bolster security in ever-changing multi-cloud setups. This ability to simplify detection and response makes AI an essential tool for managing risks in today’s cloud ecosystems.
Why is monitoring identity and access so important for multi-cloud security?
Keeping a close eye on identity and access is a key part of maintaining strong multi-cloud security. When you're working with multiple cloud providers, the chances of security gaps, excessive permissions, or misconfigurations increase significantly. These vulnerabilities can quickly spiral out of control if not properly managed.
This is where a centralized and well-structured Identity and Access Management (IAM) strategy comes into play. By implementing consistent controls across all cloud environments, IAM ensures you know exactly who has access to which resources and why.
The benefits are clear: fewer human errors, blocked unauthorized access attempts, and a stronger overall security posture for your entire cloud setup.


